スポンサーリンク

【SEO対策】robots.txtはクローリングに何をもたらすか【Google】
 マーケティング最新
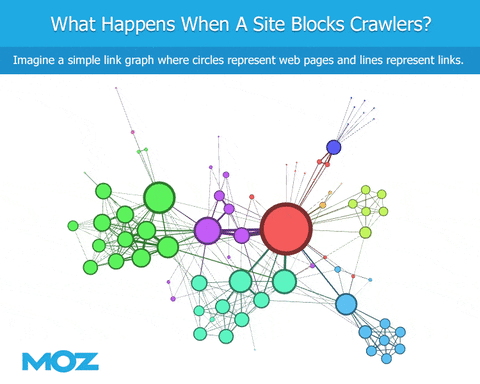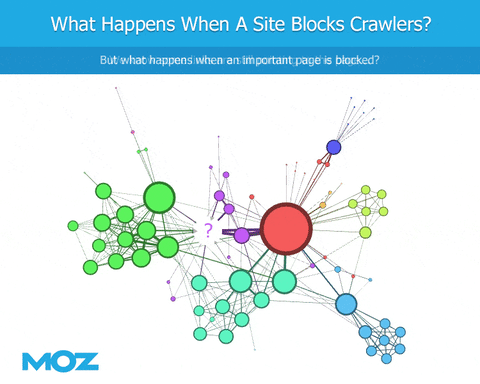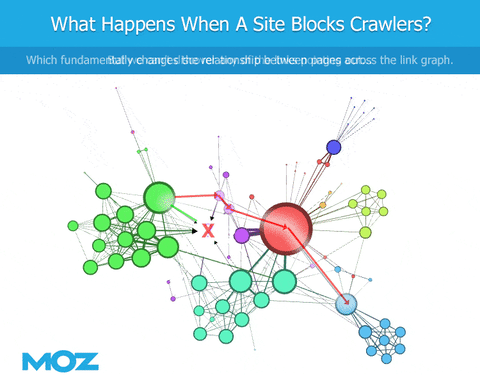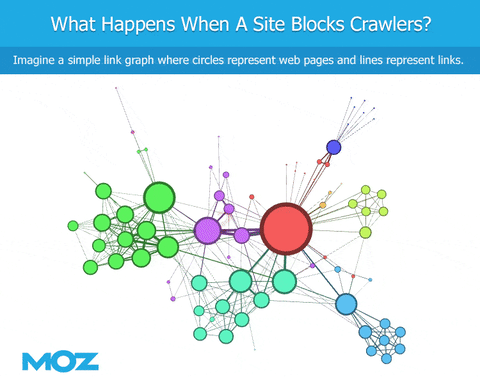
マーケティング最新ここMozでは、特にウェブをクロールする方法で、できるだけGoogleに類似した、LinkExplorerを作成することに力を入れています。以前の記事では、パフォーマンスを確認するために使用したいくつかの指標について説明しましたが、今日はrobots.txtの影響とWebクローリングについて説明することに少し時間を割きたいと思います
ほとんどの方は、ウェブマスターがGoogleや他のボットにサイトの特定のページだけを訪問させる方法であるrobots.txtのことをよくご存じの事と思います。ウェブマスターは、特定のボットにいくつかのページを訪問させ、また他のボットへのアクセスを拒否することができます。これはMoz、Majestic、Ahrefsなどの企業にとって問題です。GoogleのようにWebをクローリングしようとしても、特定のWebサイトではGooglebotへのアクセスは許可されていても私たちのボットのアクセスが拒否されることがあります。でも、これが問題となる真の理由は何なのでしょうか。
何が深刻な問題なのか
クローリングを行う際、ボットがrobots.txtファイルに遭遇すると、特定のコンテン

コメント